
Since several years, micro-service architectures became a de-facto standard for the design of medium to large scale distributed applications. Building a larger solution out of the orchestration of many smaller services, each being its own deployment unit with a bounded context and a well-defined interface, typically integrated via asynchronous messaging. To not repeat the concepts of micro-service architectures here, you may refer to the following books as they provide great guidance in that topic:
- Building Microservices: Designing Fine-Grained Systems
- Microservices Patterns: With examples in Java
- Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith
Reading though these books, you will learn that the micro-service architecture approach has several benefits but also challenges and considerable drawbacks, such as increased integration complexity. And you learn that it needs to be accompanied by fitting development & operations processes such as Scrum and DevOps and organizational structures, such as two-pizza teams and/or SAFe in order to contribute to sustainable business success.
While building and operating a micro-service based architecture on AWS is well documented and has a lot of technology support, there is an emerging trend that does not yet have this maturity: Extending the concept of micro-service architectures to data-provider services. This article will summarize elements and requirements that were observed in several customer projects that dealt with the question “how to optimally distribute data between multiple parties and leverage the benefits of API-driven service monetarization”. So, it is about the question how we can build data-provider services, aka data distribution platforms, that use the concept of micro-service architectures and provide reusable concepts also to control, monetize and operate those services at scale.
All this is put into context of available technology on the AWS services in April 2020.
Recap: AWS Services that help to build micro-service based systems
AWS provides a wide set of services to support micro-service based systems. Here is a list, along with the purpose of the service in such an architecture:
- Virtual machine based hosting and runtime
- Elastic Compute Cloud (EC2) – Run micro services on a self-managed orchestration layer
- Container based hosting and runtime
- Elastic Container Service (ECS) – Run and orchestrate Micro-Service in containers
- Elastic Container Registry (ECR) – Store and provision container images
- Elastic Kubernetes Service (EKS) – Run and orchestrate Micro-Service in containers
- Fargate – Run and orchestrate Micro-Service in containers with minimal overhead
- Serverless hosting and runtime
- Lambda – Run micro-services as event driven functions
- Networking and endpoints
- API Gateway – Provisioning of managed API endpoints
- Route 53 – DNS services with geo based load balancing
- App Mesh – Central control and orchestration of micro services
- Elastic Load Balancing (ELB) – Load balancing across multiple instances
- Orchestration and integration
- Step Functions – Orchestrate workflows and call Lambda functions
- Amazon MQ – Managed Apache ActiveMQ, for advanced message based service integration
- Simple Notification Service (SNS) – Messaging in Publish / Subscribe pattern
- Simple Queue Service (SQS) – Messaging based on queues
- Amazon EventBridge – Serverless event bus for service events
- Amazon Kinesis – Data streaming between services
- Amazon Managed Streaming for Apache Kafka (MSK) – Streaming and data processing
- Develop, build and deployment
- CodeBuild – Build deployment units from source code
- CodeCommit – Code repository
- CodeDeploy – Automated deployment of services into runtime
- CodePipeline – Continuous delivery
- CloudFormation – Automation of infrastructure provisioning
- Monitoring
- CloudWatch – Collect runtime metrics, alarming, dashboarding
- CloudTrail – Audit logs for service API invocations
- Security
- Amazon Cognito – Identity management for applications
- Certificate Manager – Provisioning of certificate for SSL/TLS based encryption
- Secrets Manager – Management of shared secrets, e.g. for internal system access
While this list may be extended with database service, data storage systems, analytics and machine learning services and much more, it provides a foundation to develop, deploy and operate a micro-service based system. Now let’s look at the specifics of data provider services.
Emerging from a data collection to a data distribution solution
Data is the new oil. Based on this much-quoted statement we see a lot of movement towards data-driven businesses. Collecting data from a variety of sources and finding new insights from that data is a common theme. Data analytics and machine learning are at the fingertips of every developer and teams have learned how to collect and prepare data so that it becomes useful.
In many cases, we can observe a plot similar to this:
- A single project is established to identify opportunities around a given set of data
- Data is collected more frequently and in larger amounts, data cleaning and pre-processing is automated
- Insights are gained and eventually a new business is born that turns the collected data into valuable insights for the customer – the project is a success
So far, this is not a big surprise. However, we came across several cases where the success of such a project led to more, bigger ideas. Since the organization now has a curated data set and mechanisms to collect, clean and prepare data, the thought to scale the usage of that data and make money from it is obvious. So, we can observe a behavior pattern, turning successful data driven projects into data provider platforms, or data distribution platforms. The business model is typically one of the following:
- Enablement Business: Provide data ingest, cleaning, preparation, storage and provisioning services, paid per data volume. Typically to enable others to work on the available data and build new on-top applications and services.
- Insights Business: Provide high-level semantic API services or full-fledged dashboards that allow to consume insights, not data. Typically paid per insight, with a price depending on the value of the insight.
- Platform Business: Provide a system that brings together data providers and data users in data marketplace. Here the platform does not interpret the data but just links prosumers on technical and commercial level (please refer to this book for details on this business model). Typically paid in a share of the price for the data (similar to a transaction fee).
While the art of building a successful software platform is another topic that requires in depth analysis, I want to focus on the element of building a data distribution platform specifically – with the key architectural approach of micro-services.
I will only focus on option 1) from the above list, since it is the most common case in what I have seen so far. Options 2) and 3) require a set of different functionalities and may be in scope for a later paper.
From single project to multi-client platform
During the transition from a single project solution towards a platform that serves multiple clients, which consume data from it, it is a long way. There is a set of challenges to consider and a set of system attributes to design for. Here is a short list of headlines, which forms the high level requirements that drive architectural decisions:
- Support multi-tenancy – serving data from/to multiple clients / customer / use cases over a shared infrastructure. This is specifically a security challenge. Please see this whitepaper for several strategies how to achieve tenant isolation in AWS. Specifically, you need to solve the following problems:
- Implement a secure data isolation, so that one customer cannot access other customer’s data in any scenario
- Handle the ‘noise neighbor’ problem, implementing measures that a single client cannot bring down the platform performance and so degrade the experience for all other clients
- Allow metering (and billing) to determine which client generated which load on your system: Number of API calls, amount of data moved, …
- Find a balance between cost and performance. There might be different data consumption patterns for all the different clients you will have. Most of them you will not know when you start designing the system
- Ensure a business model that is focused on value, hence bill your clients along the lines of usage and data consumption. For that you need the technical foundations and statistical data.
- Consider that your primary user is a software developer or data scientist who wants to ingest and/or pull data from your system. So you need to provide comprehensive documentation and examples on developer level.
- Data models change over time. Your APIs should be stable. This a conflict that needs a good strategy, implementing a concept for API management that allows flexible data models. Specifically, when it comes to how the data is presented to a client, flexibility might be required.
- Consider how clients consume data, first of all – how do they know which data can be consumed. Consider data subscription concepts or a data inventory catalog where clients can pick and choose from (along with a price tag?).
There is more around it, specifically when you want to build a sustainable platform business. But let’s stick to the above for now and see how we can address these challenges.
Observed key functional requirements for option 1) data distribution
From the projects we have seen, it seemed that the key architectural drivers on the functional side are around how the clients use the data. What we collected in the following:
- Customers are building web-applications and dashboards that require web-enabled interfaces to consume data. Typical technological interfaces here are HTTP based request, using RESTful APIs and JSON payloads. These interfaces need to support authorization, pagination and other web-UI typical function.
- Customers use business intelligence tools like Tibco Spotfire or Amazon Quicksight and need their data accessible via standard SQL interfaces like JDBC or ODBC. This typically requires any sort of Database or tools like Amazon Athena to provide a SQL query engine.
- Customers require file based access to data so that they can use it with custom application or analytics engines like Spark, Hadoop, Amazon EMR or even use it for machine learning, e.g. with Amazon Sagemaker within their own AWS account. Also downloads into virtual machines or local machines might be required. Such files might be really large and so transfer via web-APIs like RESTful APIs is not feasible. Also via JDBC or similar protocols, this kind of mass data transfer is not effective.
- Customers build applications that need low latency data updates, event driven. Running queries continuously is not efficient, so the technical requirement comes to message based push of data, e.g. by providing queues, topics or streams as transport layer. The data distribution platform then shall actively push out new data so that clients are automatically receiving new data sets. Here, it is advisable to separate between 4a) message based and 4b) stream based data interfaces
While these 4 scenarios generate completely different technical requirements and so require different technology to transport data, they have one thing in common: You cannot know upfront how the queries and data volumes will look like. So, you need to design a system that decouples the data consumption of the different clients so that heavy queries cannot effect other clients. The query behavior of your clients determine the scale of resources you need to provision and so have massive impact on cost.
Therefore, each client needs a dedicated set of resources and you need to be able to bill customers based on their usage.
Why not using simple authorization mechanisms?
AWS service provide a variety of authorization mechanisms that would allow to grant your clients access to data in your data pool. Here is a short list of the most often services to build data lakes and data pools:
- Simple Storage Service (S3). This is THE service to build large data lakes. S3 allows to store an infinite number of files, with a single file up to 5 TB in size. With Amazon Athena you can query data on S3 directly, when it is stored in a support table like format. S3 provides several options to share data with other people, other organization and applications:
- S3 cross-region and same-region replication, with the option to replicate into another account
- Relational Database Service (RDS). Here you will find several database engines at your service (Postgres, MySQL, Microsoft SQL Server, Oracle DB, Maria DB, Amazon Aurora). While the engines of course differ in their capabilities, you can always provide database-level user authorization to grand a certain client access to (parts of) your database. So IAM policies and database level authorization play in concert.
- Any of the other databases (DynamoDB, DocumentDB, Managed Apache Cassandra, Neptune, QLDB, Timestream, ElastiCache) or the AWS data warehouse solution, Amazon Redshift: It is basically the same here. You may use IAM policies on database engine specific authorization mechanisms to grant access to data. Some engines support read replicas to design for better read performance and this can also be used to segment clients on multiple machines.
The common concept here, when you think of providing access to these data storage and database systems is, that you will expose your clients directly to your AWS S3 buckets and databases. Unless you replicate data into dedicated S3 buckets (e.g. using same-region replication) or dedicated database read-replicas you will sooner or later have to deal with the noisy neighbor problem. Such that a single client can bring your databases down with a heavy series of queries. In addition, you will notice over time that the management of policies and authorization in the diverse systems is an operational burden. At a certain scale this is not feasible and will end up in a security risk due to out of control policies. Also technical limitations like the maximum size of a policy document may play a role. Finally, you will not have any control and visibility on who did consume which data. Metering, throttling and control is hard to archive since it would require different measures depending on the used data storage technology. So, this concept of direct access management to data stores seems not to be a sustainable approach and it will not solve the majority of the above listed key requirements.
You may consider AWS Lake Formation as a service that makes it easier to set up a secure data lake. Lake Formation helps you collect and catalog data from databases and object storage, move the data into your new Amazon S3 data lake, clean and classify your data using machine learning algorithms, and secure access to your sensitive data. Your users can access a centralized data catalog which describes available data sets and their appropriate usage. Your users then leverage these data sets with their choice of analytics and machine learning services, like Amazon Redshift, Amazon Athena, and Amazon EMR for Apache Spark. Lake Formation builds on the capabilities available in AWS Glue.
While Lake Formation so help tremendously to reduce the operational burden of managing data access and pulling data into a central S3 storage, it (currently) does not solve the problem of noisy neighbors nor does it support in active and custom control mechanisms, metering, throttling and billing of clients to your data. And it allows data consumption via S3 only (which might be sufficient for you, but was not in cases I have seen).
The dedicated data provider resources pattern (aka data fan out)
As we learned, a key problem to solve is that we a) have to support at least 4 different base scenarios how data is consumed and b) at the same time be able to adjust to client specific performance / data-volume needs. The 3 Vs in big data play a role: Velocity, Variety, Volume. Every client may need data in different velocity (e.g. once a day vs. event driven on a second basis), each client may want to see another subset of your allover data set and also in specific output format (e.g. unit conversions, aggregations, transformations, data structure, …), and every client will need another volume/time amount of data.
You will find it very challenging to solve these concerns with a single database or file storage concept. Actually, we have seen such attempts and they simply did not work.
The solution is data duplication and dedicated resources per client.
Here are the attributes of the key concept in this pattern:
- You ingest data into a central data lake in a format that you control
- Clients never get access to the central data lake directly
- Clients need to define which data they need – out of a central data catalog
- Clients need to define in which technology they want the data – out of the 4 options we discussed above: Web-API, JDBC/ODBC, File, Messaging or Streaming
- Clients may want to choose from a set of performance profiles that come with different price points
- You, as the platform owner, will then create dedicated resources which you expose to your clients: RDS databases, S3 buckets, API GW endpoints, SQS queues, SNS topics, Kafka Streams, Kinesis Streams, MQ topics/queues, IOT topics, …
- You have an automation in place that allows to synchronize newly ingested data into the dedicated client resources, e.g. using CloudFormation of custom scripts using the services APIs
So, there are 3 key elements here: You need 1) a control plane where customers can manage their needs, 2) an automation that allows creation/destruction of dedicated resources, and 3) a data pipeline system that knows which output channel shall receive which data.
Here is a sketch that illustrates the concept:
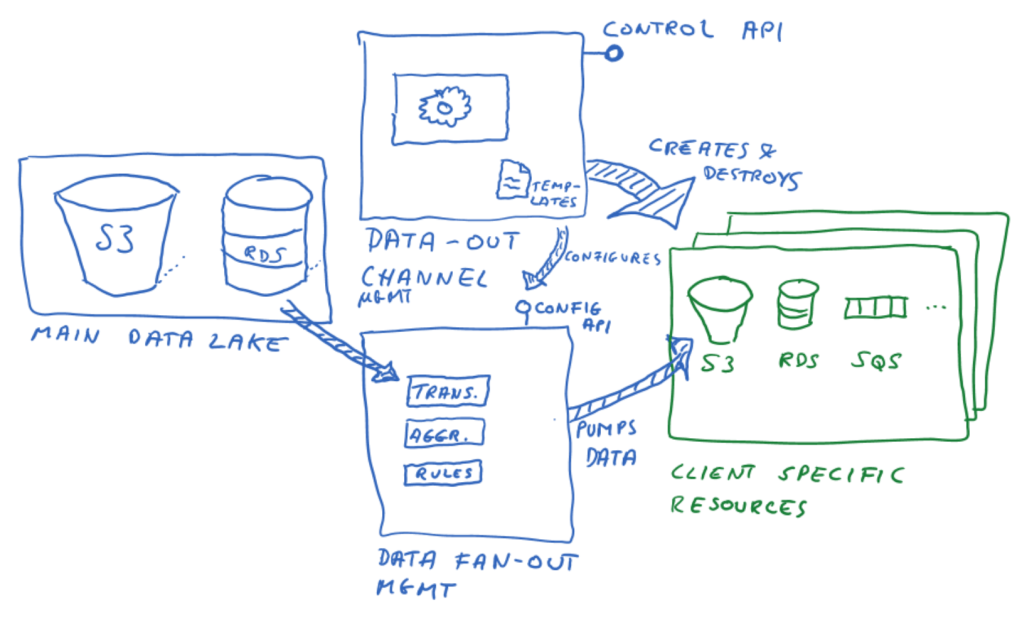
We can already identify 3 functional domains, separating concerns in the solution:
- Storing the main data set in a central data lake, along with required management functions
- Data-Out channel management with the customer facing control API
- Data-Fan-Out management which needs a configuration API and inner functions that allow to bring the data from our central data lake into the desired client specific technology and format (at least including transformations, aggregations and fan out rules)
You may now wonder that this is an expensive solution. Yes and no. It is of course more expensive at first sight, since you need multiple resources and duplicate data a lot. But: you can directly express the value of that cost and you can explain that to clients so that you can generate price tags that are still reasonable per customer. The other option would be to work with a central god-like data storage that can manage all 3 Vs requirements for all clients. While this is technically hard to do, it will also generate massive cost because your scaling requirements would be the superset of all client scenarios combined. This will NOT be cheaper (pending measured proof) if feasible at all.
The control layer API pattern
Let’s have a closer look at the control layer API and data out channel management.
The control layer must enable the following business functionality:
- Expose a web-API that allows the required client actions. This could be achieved e.g. by using AWS API Gateway.
- Authenticate and authorize client requests. This could be achieved e.g. by using Cognito or Lambda custom authorizers.
- Allow clients to specify what they need, see above. Here you need to specify the API.
- Create resources based on client request. Here you might implement direct calls to the respective AWS services or better use CloudFormation templates in conjunction with the CloudFormation service.
- Delete resources based on client request.
- Configure the data fan out so that new resources receive data, based on an internal API that the data fan-out service would expose.
- Collect statistical information about client activity that can be used for auditing and billing. Here, a separate micro-service is advisable, it is a concern of its own.
When thinking about a design for such a control layer API, let’s work backwards from what the customer needs:
- Clients need to define which data they need – out of a central data catalog. This demands for another service we should design: a data catalog service which knows about all data that is available for a given customer (authenticated to use). This service may be used here to compile a list of elements and provide it back to the client.
- Clients need to define in which technology they want the data – out of the 4 options we discussed above: Web-API, JDBC/ODBC, File, Messaging or Streaming. Here you may think in profiles. The resource creation shall be limited to a pre-defined set of templates and you can expose those on the API as options to pick from.
- Clients may want to choose from a set of performance profiles that come with different price points. Here, this may depend on the used technology. When providing a RDS database, you could use larger instances and read-replicas to improve query performance and so map that to a price point. When using Kinesis or Queues for messaging / streaming you can decide to build multiple shards which you can also offer at different prices. Here, it makes sense to offer the technology options in different T-Shirt sizes.
Example: In order to create a new data-out channel, I could craft a call similar to this (simplified):
GET https://somedomain/myaccount/data-out-api/v1/out-channel
{
Data: DataCatalogElementID
ChannelProfile: JDBC
PerformanceProfile: Large
OutputDataModel: SomeComplexDefinition
}
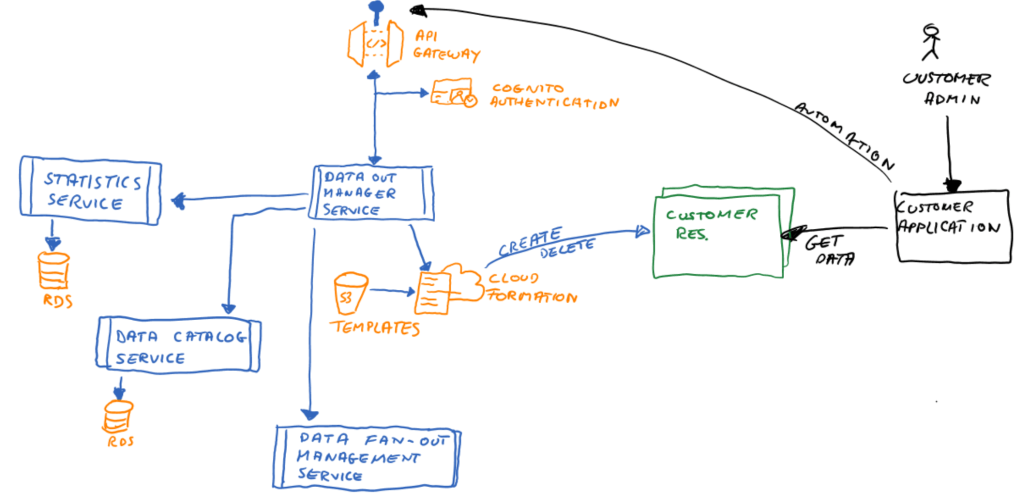
Keep in mind that the creation of the required data out resources may take a while. Also, the data fan out service needs to establish a data pipeline to fill the new resource with an initial data set and keep it updated. This all takes time and so a client requests to create a new data out channel can only be done asynchronously. Think of an out-channel-creation-order and an event that notifies the client when the resources is available.
As result event so shall of course include all data that will allow the client to access the resources (URLs, authentication credentials). In order to make this work, you need to create credentials and manage IAM policies to the dedicated resources. But since all this can be automated, the data out manager service can do all this as part of its business logic.
Note: In front of your API Gateway (data-out API) you can of course place a web user interface that uses the very same API if you want to enable human users to administrate their data out channels. Here you could use a static web page hosting using S3 or any other web-serving option (e.g. AWS Beanstalk). In any way you should make use of the same API from that UI, so that there is no difference in the implementation of the API business logic.
The inbound and outbound channel pattern
As I outlined above, you can use the control layer to allow clients to create new data-out channels. The same concept however can be applied to data-in channels.
There may be a set of different ways how data is ingested into your platform. Technology and protocol wise, they can be the same choices as the data-out channels. Typically, IOT devices that are inserting data via MQTT messages play a larger role these days, so that this might be an additional option.
But the concept is the same. You may add a Data-In Manager service to the system.
Data-In channels however trigger data ingestion pipelines. So, when creating data-in channels user may choose to define the input technology but also the input data model in order to allow you ingestion jobs to transform and clean the data automatically towards your central data lake’s model (if there is any). For managing ETL jobs with Spark, you may want to consider AWS Glue.
When applying this concept, you will create a data landing zone with dedicated ingest resources per client. From there you need to automate the data fetching. Moving the data into your lake in a controlled fashion, dealing with data loading and write capacities of your lake.
In addition, this process needs to feed the data catalog with new elements, so that clients can make use of the new data subsequently.
Data processing and latency considerations
One key challenge in this concept is to automate the data pipelines between the data-in channels, the central lake and the data out-channels. There are two main questions to answer:
- How long does it take that data that is ingested in a data-in channel becomes available in the data out channel(s)?
- How do you manage transformation rules and data model differences?
Starting with the data ingest, it might be required to differentiate the timely behavior of your platform. Clients may choose a cheaper version where data is processes in fixed intervals (e.g. every hour or once a day), or a more expensive version where data is processed in the moment is inserted in a data-in channel. So, this might be a parameter at the data-in channel management API.
You can basically process all inbound data in batches to optimize for cost, when you land all data from all inbound channels in a persistent landing zone. So, you could write a simple function or use Amazon Kinesis Firehose to first store all data in S3, even those data sets that are coming in via messaging or streaming channels. Then you can use AWS Batch, AWS Glue, custom Lambda functions or processing services in containers to work on the new data with a controllable amount of concurrency and performance.
You can also implement event driven, direct processing of each individual data set that is flowing in. While this is natural for message based and streaming based systems, you can also use this on S3 with put triggers, by triggering Lambda functions to directly process data once it landed in S3. Similar, if you provide an Aurora database as data-in channel, you can invoke Lambda functions when new data is inserted (via insert trigger). In principle this allows to directly process, transform, clean and insert data into your data lake immediately.
While batch processing can be more efficiently use resources and so may be cheaper, an event driven / immediate processing may be required to eliminate wait times. In both cases, once this processing is done, you could use messaging to inform the data-fan-out service that new data is available (for a given scope). With that the data fan out service can start functions or processes to get the new data and transform & insert into all subscribed outbound channels. Such, implementing an event based data processing pipeline avoids long latency but minimizes it to the time it needs to transform and load data. This processing time can then be influenced based on the amount of concurrency you design into the system.
Data catalogs and making data sets findable
You may have noticed that once central element to the entire concept is the data catalog. Data fan out only works when each outbound channel has a well-defined scope as a subset of the data that is available in the entire data lake. Also, when new data is coming in on data-in channels it would be required to know if that data is in scope of any of the outbound channels so that they get updated. Now, the question is how to manage the data catalog so that it allows all these cases?
Optimally, we might assume that all data that is inserted provides a self-describing set of meta information with it, from which we can derive all required information that we can use to advertise the data catalog and use in the synchronization over the data-fan-out service. AWS Glue has features that will crawl data in S3 to find columns and headlines in your data files. While this is great, it requires that data is available in table-formatted files (e.g. csv, parquet, …) and in addition does not provide any semantic context. To make this work, you need to define meta data interfaces and how data that is provided in data-in channels is augmented. This might be difficult to achieve as long as the different data sources provide data in different formats.
A more lightweight first approach could be this:
- When a client uses the data-in channel management API to create a new data-in channel, the client has to supply mandatory meta data.
- This meta data could include information about the context, the source and the format of the data that will be provided. It certainly should include information what data is transmitted via this channel and how this data is identified.
- With that, a concrete inbound channel (e.g. a messaging topic or a S3 bucket) have a defined scope, known context, known content and can so be catalogued.
- The data catalog service can then generate unique IDs for each data set that was provided in this way, and those IDs can be used for subsequent subscriptions and data synching functionality.
The provided meta information may be high level and rough and may not even detail individual fields and attributes in data sets, but still it could be used to identify these data sets. This concept can be enhanced with details of the data model, semantic meaning and other elements if you want to go far. Also automatically extracted meta data like column names or field names in JSON documents can be used here to automatically enhance the catalog. But to start simple, you can work with basic meta data as outlined above.
Using machine learning and deeper analysis you might leverage advanced concepts to tag data, find relations and semantic meaning in data which can be advertised on top via the data catalog.
In all cases, you would need to be able to build a multi-dimensional hierarchy of data elements that all have unique IDs, so that a client can subscribe to a concrete subset of the catalog. And… not to be forgotten, the catalog must enforce that clients only can access the data that comply with their authorization policies.
Conclusion
This article proposed a micro-service based architecture for a data distribution platform that allows client specific billing based on used resources and statistical data. This solution may be act as a conceptual template with a few patterns to choose from. Of course there are many more details you can discuss in the complete solution, however the concepts outlined here on an architectural level should solve the key requirements that we outlined in the beginning.
The complete picture shown below. Please remember, each micro-service should follow the best practices of micro-service design, we did not detail this here.
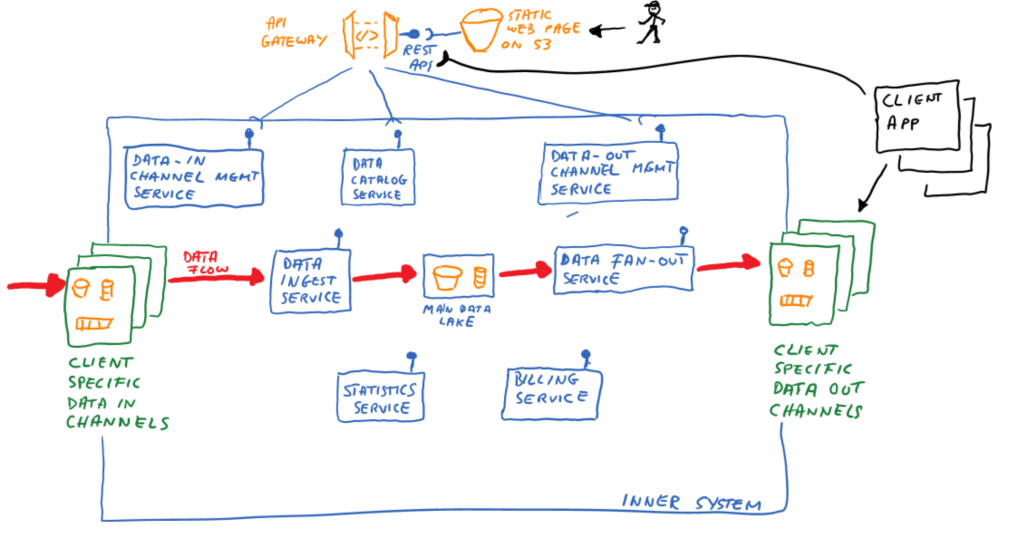




Leave a comment