
When organizations build individual software solutions and products over the years, at a certain point in time it seems reasonable to consolidate the existing solutions and extract their commonalities into a shared common asset – called software-platform. The reasoning is often based on the assumption that the platform – as shared asset that is reused in the existing systems – must be maintained only once and allows reduction of cost and shorter time to market for new solutions. However, the challenges within this approach are often underestimated which may lead to exactly the opposite than the expected cost and time savings. This paper outlines typical pitfalls and challenges and provides best practices of how to approach a migration to a platform approach successfully.
First of all, I like to point out what this paper is not: it is not a paper that explains how to build a software product from a SW engineering point of view. The art of creating good software solutions is covered in many books and articles, to which shall be referred at this point. This paper is also not a re-definition of Product Line Engineering (PLE) for software products. This topic is also covered in literature and discussed widely in conferences and expert groups. However, this article tries to highlight the best practices of both disciplines in the area of platform scoping and platform definition in addition with the aspect of human centric issues (social and organizational things) in order to provide a more holistic view on the challenge at hand.
PLE professionals may complain about the more simplistic view on PLE that is used in this paper. PLE is a complex and well defined methodology and collection of best practices for building product lines. So, yes, there is much more than what is outlined in this paper. For everybody who intends to set up a real product line based on existing solutions / applications and products therefore it is strongly advised to get more information on PLE in addition to this paper. Just building a platform will not be sufficient for such an undertaking. The books mentioned in the references can be a starting point.
The goal of this paper is to first provide a general overview on the challenge and the complexity of a platform approach based on existing solutions. Here, the technical complexity is one central aspect but also non technical aspects typically lead to severe problems during such an undertaking. Missing acceptance of the approach, unexpected costs, technical problems on the way and a striking resistance of people to abandon their old habits all lead to the fact that many such approaches remain unsuccessful. Secondly, this paper will highlight a few best practices, from the existing PLE frameworks, from software architecture but also from a peoples-cooperation point of view, that help to deal with the complexity and handle the risks. Even for projects and people that are either not aware of PLE or simply do not want to follow a product line approach, some of the PLE methods can be used to strive for a less risky implementation of the platform approach.
Also please note my former article on “How to avoid Cost Traps in Platform Development” which was written before as part of this series on Best Practices in Platform Development.
At this point please also note: Consider well, if you are planning to create a platform. When thinking of all consequences and total cost of ownership, sometimes individual solutions are the better variant. As any technology, platforms are no silver bullets.
This article will first introduce into some terminology to avoid misunderstandings. In chapter two it is discussed what the expected results and the reasoning of starting a migration platform project might be. Chapter three discusses the details on the contents of a platform approach and what it actually means to extract parts of existing solutions while chapter provides some hints for the practical way of doing it.
What is a Platform?
There are many definitions for this term in computer sciences. In this paper, the term is about software platforms and is used according to a definition that can be found in several papers and books:
“A software platform is defined by a well specified interface that allows other software to be built on top of it.”
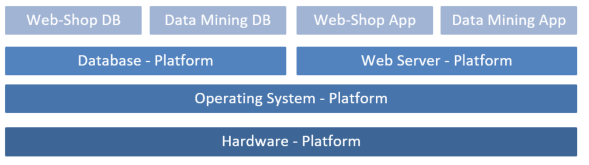
Figure 1: System of PlatformsSo, it is about functionality that is provided by a set of software which can be used by other software. For that the SW platform can be provided in multiple ways: as a binary library, as pure code, as a complete product, as software as a service in a cloud environment or in any other provisioning. The point is that the functionality is accessible by other software through a defined interface. This interface in turn also can be provided in different ways: as code level API, as a web-service, via a message bus, via an SQL statement or stored procedure or in any other way. Such a software platform so provides the underlying layer(s) in a system that is more specialized to serve a more concrete business.
A product or solution of one organization may serve as a platform for the next. As long as the layers provide public interfaces to re-use their functionality, they can be defined as a platform.
In the larger context of product line engineering, the platform will provide the common assets that are going to be reused in the products that are developed in the scope of the PLE approach. So, the platform becomes the technical enabler on which the products will be set up. Due to its business impact – positive and negative (e.g. in case of quality flaws) – the platform needs special attention in all aspects; during the planning and the development process.
What is Product Line Engineering?
Before diving into the topics, a very brief introduction into the part of PLE which is relevant for this article shall be provided. It is intended for those readers who did not yet have contact with PLE before. Because several methods of PLE will be mentioned in this paper, the context shall be outlined beforehand. Please note that only a small subset of the large PLE toolset is mentioned here, primarily in the context of platform scoping.
The content which I present here is mainly based on the training material provided by Christa Schwanninger (Siemens AG).
A general definition of PLE was so provided as:
“A software product line is a set of software intensive systems sharing a common, managed set of features that satisfy the specific needs of a particular market segment and that are developed from a common set of core assets in a prescribed way.”
The main characteristics of a product line so focus on three aspects:
- Business driven: All products and so also the shared assets are shaped and defined because of market demands and business considerations. A global optimum over all products is in focus, not the individual optimum for any product.
- Managed variability: There is a clear and explicit process of identifying and managing variability and commonality between products on all organizational levels; and over all phases of the product lifecycle.
- Strategic reuse: Reuse is planned and part of the product strategy and the product portfolio. This also spreads over all products of a product line and so all involved organizations. So, for example, the reuse and its impact is not necessary limited to a single department.
From these very basic aspects it becomes clear that PLE does focus on a broad and global optimization of product development. It so automatically dives into processes and organizational topics and provides tools for managing and modeling the artifacts that are required to execute such an approach. At its core, the PLE approach relies on a selection of target products and a clean analysis and modeling of the commonalities and the variabilities among the planned (or existing) products in order to determine the scope of the shared common assets. Some of these common assets may then be realized into a software platform which builds the basis for the software products of the product line (which does not only apply to SW projects). In order to do this, a complex organization with many departments must be able to execute a joint business plan. Organizational and process topics need strong consideration as well to overcome critical issues concerning responsibilities and forces between departments and groups.
For the realization of shared assets and applications, PLE distinguishes two main development processes. Both include all steps from requirements engineering over design and implementation up to test and release:
- The so called domain engineering: Since the shared assets (including a SW-platform) will include features that are typical for the market segment of the product line, it has a clear focus on the domain for which the products are used. So, the engineering of the platform (or the core assets in general) is called domain engineering.
- The so called application engineering: The products that are built on top of the platform form applications that can be sold to the customer and which are visible in the market. Application engineering so refers to the creation of the very products that generate the profit for the organization.
Now it seems interesting what the actual difference is between a “normal” SW-platform and a SW-platform that is created in the context of a product line. The border is not sharp but there are several aspects that make a difference. A classic software platform is also specific for its domain and it also contains all features that are common to all the solutions that are built on top of it. However it is not necessarily clear who will make use of it. If we think of general SW-platforms like the .NET programming language, the Boost c++ libraries, a API for using operating system functions or the eclipse project, none of these platforms do know who will use how much of the features that are provided (absence of explicit application engineering). They are more generic and their domain is in the area of technology and/or basic infrastructure.
In PLE, the platform is shaped and scoped only to optimally support a known set of products. So, the platform may also include some product features already with essential variations for the different target markets. The focus here is on the effective provisioning of the products. So, these platforms are more specific and their domain is in the area of a companies’ business segment. (Note: Of course there are companies that build infrastructure software as their main products, so their business is general purpose platforms, which in turn might be based on internally shared platforms as well).
While talking about Product line engineering it also must be said that the same approach also is valid for a solution business. In solution business, not products are created but individual customized solutions are created for different customers. This is not a mass production business and typically the order numbers are small. However, the need for effective and fast engineering is also crucial to the cost position in a competitive market. And so also in solution business it makes perfect sense to provide assets that are common to all solutions in a shared platform; which can be archived with the very same methodologies that PLE promotes – of course tailored to the needs of solution business.
For more information on PLE please refer to the vast amount of PLE literature, for some examples please see the references in the end of this paper.
How is PLE to be understood for this paper?
As outlined above, PLE provides several tools and methodologies that form best practices for building a product line. In the context of this paper only the aspects for scoping the platform are considered and mentioned.
Why do we want a migration of existing Solutions to a Platform Approach anyway?
Some typical Examples
As a starting point, it shall be discussed how a business owner or R&D manager might come up with the idea of extracting the common assets of multiple existing solutions or products into a platform. The examples are simplified but hopefully help to get a grip on the topic.
Example 1: Multiple solutions or products in the same domain
Product Business:
The most often used example for this case is the car manufacturing industry. Instead of building every car model individually, several models share a common base platform to reduce the development effort for each individual model. But let’s make a SW example. An organization has built a special operating system for personal computers a few years ago. Two years ago, the same organization also created an operating system for a special class of embedded devices while making use of the same concept that makes their OS so unique. Today, they think of creating a third operating system for a special mobile device that also shall provide their special concepts to their customers. While discussing the required work to do for the new OS, they discovered that they have to implement the very same features again which they also have for the PC and the embedded device. At least the features have the same names and roughly have the same requirements. Why do they need to invent the wheel the third time just because it is for another target device? Would it not be more efficient to create a platform which provides the common features that fit all target devices by extracting them from the existing systems? So, the new OS would directly be built on top of the new platform while the two existing systems need to be re-designed and changed to just use the extracted components. This can’t be too difficult, right. They will save a lot of money on development and maintenance of the shared components – and when they decide to create a fourth product, they will be even quicker in realizing it.
Solution Business:
Another organization is in the logistics domain, they build custom solutions for packing and sorting parcels and packages based on a consumer order system (e.g. a web shop). This year they have built 2 individual solutions for two of their customers. The solutions needed to be individual because of the different work processes and business rules the customers have. However, they needed to more or less do both solutions from scratch while several base functions seem to be quite similar in both solutions. Now they are building another solution for a new customer and it turned out that the Copy-Paste approach (they just copied the similar features by doing a code-clone from a prior project) is somehow ineffective. They still find bugs in the first solution that were also copied to the second and third solution and so they have to do the fixes multiple times (including testing and all other). It comes to their minds to extract these common features from the existing solutions so that they can stabilize this code once and for all. This also will make them faster in the third solution, when then can simply reuse the existing code without change.
Example 2: Multiple solutions or products in the similar domains
Based on the solution business example above, it could be that the R&D head of the logistics solutions department thinks: OK, we have this parcel sorting platform. We also have airport logistic solutions where we transport and sort the baggage of the passengers within the airport buildings. What is so different on sorting and transporting baggage from sorting and transporting parcels? Can we not reuse the common features in both domains? From a high level point of view, the both domains are very similar and so the features are. I like to have a more common sorting platform that serves both and saves a lot of development cost!
Example 3: Carving in or buying products that complete your portfolio
In larger organizations it can happen that a software solution or product is bought along with the department which created it to complete a product portfolio. The same situation applies when two departments which were formerly independent are merged into a single department. The two department’s products will now be under the responsibility of a single head – with the need to optimize cost over all developments.
Now the new R&D head looks at the existing product(s) and the newly carved in product(s) and may think: Nice, these two products have together all the features we need. But how can we now generate an integrated customer experience? These two products need to be integrated; at least they must provide the same look and feel and follow the same style guides. And by the way, it seems that about 50% of the features that solution A provides also exist in solution B. I do not want to pay double the maintenance cost for a redundant set of features just because they have a different history… and since we need to integrate them anyway for the user experience we can fix this right away by extracting these 50% of the features into shared components that both solutions will use.
In this example, the term “integration” comes into play. The integration of two applications or solutions is an own topic of software engineering art which has many facets. However, when integration means a merge of features and even source code, it might quickly lead to a platform approach. So integration and platform development are not the same in this context since integration can also occur without extracting common shared components from the two applications (e.g. by building a UI portal on top of them). More on this topic will follow later in this paper.
Example 4: Leveraging USPs of existing Platforms
Another example might be the following: In a larger organization a platform was developed that has some real USPs (unique selling proposition). That might be for instance a very effective maintenance concept, a very unique scalability solution, a new deployment and provisioning offering (e.g. a cloud offering) or a set of special algorithms. There might also be some existing solutions that are already based on the platform, while other solutions are not yet. For the latter the decision of the department heads may so lead to a migration of the remaining solutions to also be based on the existing platform.
Assumed Benefits
Do the above examples sound familiar? There are much more examples around, and many other situations can be described. In summary, the assumed benefits are often the same as for any platform development project. The platform development tries to foster reuse of functionality that is needed more than once in order to reduce maintenance and development cost. Maintenance is the most costly part in a software lifecycle and so any duplication of work has direct impact to the economic profit of an organization. Also, if features are provided as shared components in a platform, new products and solutions are expected to be ready more quickly when built on top of it which also reduces time-to-market. Especially time-to-market is a crucial aspect for many business strategies and so is often highly prioritized.
The other direction was provided in example 4 above, where not time-to-market or the reduced maintenance are in focus but the technological innovation and leveraging of USPs. Such a business decision then is not directly influenced by a comparison on existing functionality over multiple solutions but is driven by the idea of leveraging the platform’s USPs in the existing solutions. So the business case is more directed by strengthening the market positioning rather than reducing development cost and time-to-market in the first place. Typical examples are platforms that realize a new innovative technology or follow technological trends (e.g. virtualization, cloud computing, big data, multi core, mobile computing and similar). Nevertheless, reuse is in scope, because also the new technology needs to be used in order to gain benefit from it.
Intuitively, people find it easy to believe that reuse can lead to substantial cost reductions. As early as 1988 Gaffney et al. set out to study the relationship between the relative costs of reuse and tried to determine the effects of amortizing the costs and benefits across many re-users (in this article, the re-users are called clients of the platform). To explain this relationship, they created the Payoff Threshold. The Payoff Threshold tells us how many times we have to reuse a component before we recover the investment we made in order to develop the component. Today, it is well understood that the number of re-uses has substantial impact on the question if it was worth to build a reusable component. But what not shall be forgotten is that not only creating a reusable component is costly but also to make people re-use it. This especially comes into play when existing solutions shall be migrated to a platform approach where people tend searching for reasons against the approach.
This paper will now discuss several aspects that will lead to the idea what makes the platform approach for existing solutions complex and costly and how we can come closer to a realistic Payoff Threshold as mentioned above.
What a common Platform means
Interpreting the Term “Platform”
As outlined above, a software platform can be defined in many ways – the general term so is very generic. When starting a platform development, it first shall be defined what the target platform should be. The size, type and usage of the platform have substantial impact on the required organization of teams, of business planning and financing. It so becomes a crucial question to answer.
For example, the smallest dimension for a platform could be a small set of classes which are provided in a small tool library that everybody can download and use. So the target platform would be easy to handle, easy to use and has low impact to the organizations and solutions which make use of them.
On the other end of the scale, for example, the platform may consist of a fully fledged product line core asset which builds the basis for a variety of products – with high grade of application support. In this case the platform will be a very complex system which demands for an own organization to maintain it. It will have massive impact to the success of the products and so massively impacts the cooperation of several departments – and their financial engagement.
It is essential to be clear where on this scale the target platform shall be. The larger the platform becomes and the more organizations and people are impacted, the more it becomes a product line approach. Beside the pure technical challenges, also the organizational and human-centric challenges become more and more substantial to the success of such a platform development project.
The answer to this question can be derived from a sound business planning and the business strategy. Business owners, product owners, R&D managers and project leads should agree on the business scope of the platform in order build the foundation for the technical scoping. This step is essential also to early identify the involved stakeholders and the monetary impact to different departments.
The real Similarity of the Solutions in Scope
As shown in the examples above, typically the idea of creating a platform from existing solutions is born on a functional level. And it is a valid starting point for a platform approach.
From a high level view, the applications or solutions that are in scope should be analyzed to find overlapping functionality that may be worth to be extracted. Of course, only features that exist in multiple existing systems make sense to be extracted in order to gain a reuse factor that is greater than one.
While doing this, typically a difficult question draws the attention of the involved stakeholders. How deep shall we go with the analysis? As usual, the devil is in the details and should not be ignored. I like to make an example that hopefully is somehow transferable to other examples. Let’s assume we have two larger applications that shall be integrated based on a common platform. The 10.000 feet architecture of both systems is as follows (artificial):
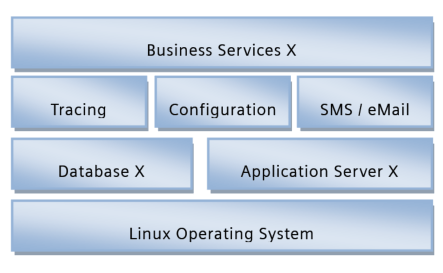
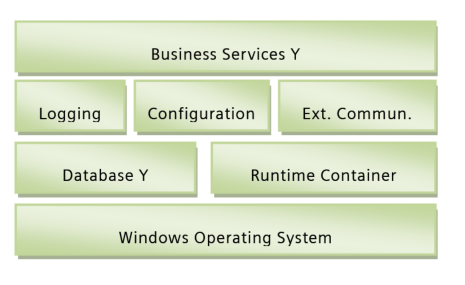
The both architectures look very similar; they share the same concept that the business services are based on 3 basic feature components “Tracing (A) & Logging (B)”, “Configuration (A)” and “External Communication (B) via SMS / eMail (A)”. Both use some kind of Database and a runtime container in which applications are executed. So the target is set to create a platform that covers the first 3 layers in this system based on the 10.000 feet similarity of these 2 systems. The business services would then be the applications that are built on top of the platform. By the way, this automatically would mean that both solutions and the platform would need to run on Windows and Linux?
Here is a potential target setup, with the platform being the orange components.
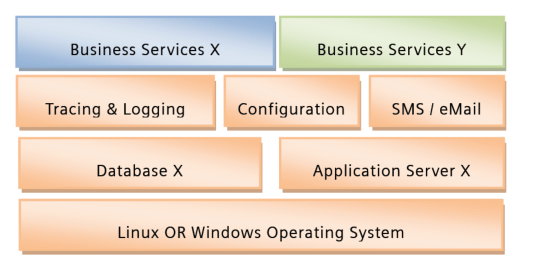
In reality we will not be able to determine the cost and risks for the realization of this approach from the 10.000 feet view, so we need to dig deeper.
Application Integration in a nutshell
The integration of applications and solutions can be very diverse, depending on the actual need and the goal of integration. In this paper, I refer to the so called horizontal integration of two applications or solutions.
In contrast to horizontal integration which links two solutions on the same level of an IT infrastructure, vertical integration deals with the integration of solutions of different layers within an IT portfolio. For example, the integration of a customer relationship management system with a production planning system and the production automation control system can be seen as vertical integration. Such systems follow different paradigms and work in different domains. Vertical integration so has to overcome the differences in paradigms in different IT domains.
In horizontal integration however, the applications in scope are typically located on the same domain or level of abstraction. Here I assume that the two applications that shall be integrated are of a similar kind.

Figure 4: Levels of application integration
The illustration above shows the basic idea of horizontal integration. Applications A and B are split up in their basic concepts and layers of responsibility. When thinking of how to integrate the two applications and e.g. extract / combine their common features into a platform, the following main aspects shall be analyzed:
- Data: How is data structured and organized? What are the semantics and how is data labeled, indexed and linked?
- Data Storage: How is Data persisted? Which technology is used and which performance qualities are required?
- Data Access: How is data accessed by the applications? Which interfaces are required, which queries are done and how much data is transferred?
- Middleware: Which technology is used? How do applications communicate and exchange data? How are applications executed and controlled? How are they instantiated and configured? How is logging and error handling done and how are security and performance requirements realized?
- Applications: Which business logic is supported, which features provided? How is it variability realized? Which data does an application provide and which data does it need? Which interfaces are supported? Which dependencies exist, also to external systems?
- User Interface: Which technology is used, which look and feel is provided? How is the interaction philosophy designed, for which user process is it optimized?
The stack can certainly be defined differently, depending on the application or solution, however the essence of the above is: It is necessary to understand on which level integration and harmonization of the two systems is targeted. In order to generate a platform that is serving both applications as basis, the differences in both applications need to be harmonized or merged since the platform can only be implemented in a single way – which needs explicit decisions. In general, for all system parts the following dimensions need to be considered:
- Used technology (e.g. which products, libraries, frameworks and other platforms are used)
- Implementation language and implementation philosophy (e.g. Java, c++, c#, JavaScript, SOA…)
- Data modeling and data exchange paradigms (e.g. message driven, event driven, polling, files, transactions…)
- Baseline architecture (e.g. encapsulation and interface concepts, components and modules)
- Runtime deployment concept (e.g. application container, operating systems, hardware)
- Functionality (e.g. what is it doing)
- Quality (e.g. how is it doing it, performance, security, scalability, availability …)
- Dependencies (e.g. which interfaces are expected from other features and modules)
From a feature point of view it may happen that not only the application layer is involved but all of the aspects mentioned above (as indicated with the blue boxes in the image above – example “logging feature”). A concrete business feature will have structured, persisted data that needs to be accessed by applications and it may also have UI elements to expose data to the user. If now two solutions implement the same business feature it might be reasonable to extract this feature into a platform, however then the platform may need a single concept for data persistence, data exchange, application hosting or UI. In here, the complexity of the approach rises and so needs special attention.
The more differences between the two existing solutions we find on the aspects outlined above, the more difficult will it become to “extract” features from one solution and reuse them in other existing or new solutions. Since specially the infrastructure decisions (e.g. database, communication system, data provisioning, tracing & logging, configuration…) have massive impact to all higher level features, it can be expected that reuse of platform features requires adapting to the platform’s infrastructure and used paradigms. This is less of a problem when creating new solutions on top of the platform but may lead to substantial cost and risks for existing solutions that shall be changed to make use of the platform in a later stage of its lifecycle.
The devil is in the Detail
When looking at the example given above, the orange target platform should contain the feature “logging & tracing”. It is called “tracing” in solution A and “logging” in solution B.
Based on the aspects that were mentioned, we now compare the two components in solution A and solution B to identify the differences on a more detailed level. Of course this is just another rough example which would be more elaborated in real world cases:
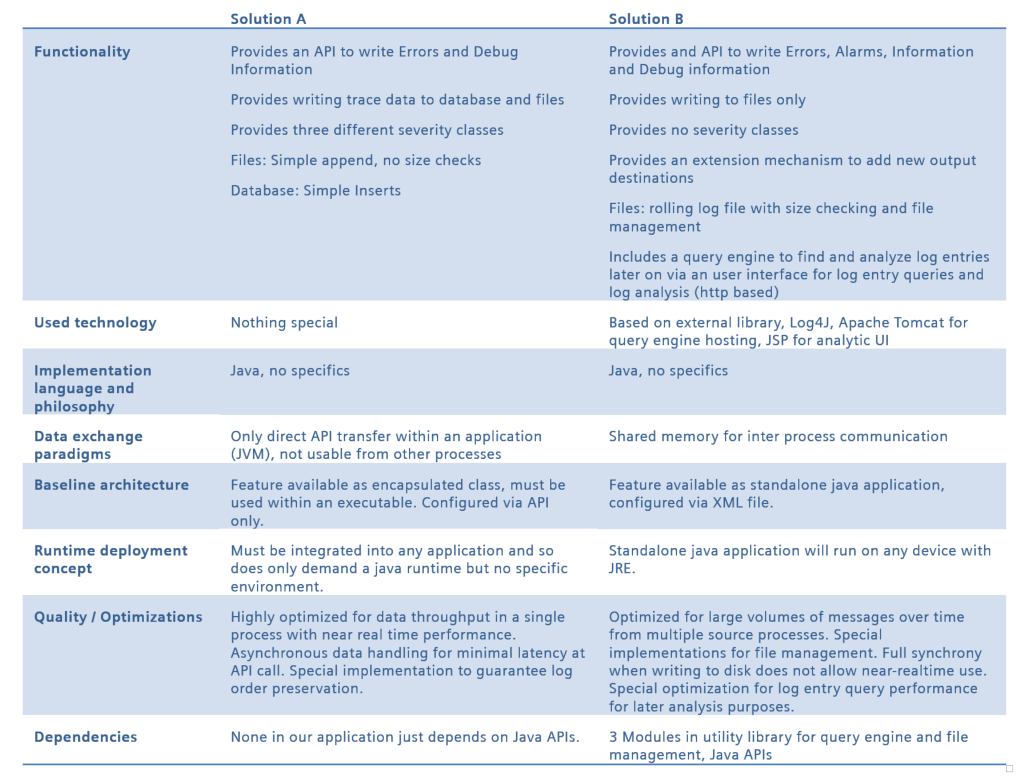
Table 1: Example Implementation Comparison
This example is a bit artificial but it shows the differences. Application A uses a high performance system that only provides the basic logging features but at maximum throughput. So, the implementation of application A handles the lifecycle of the trace component since it is not available as standalone module or application. This already includes some hints on how the use of the component would necessarily look different in application A then in application B. Application B encapsulates the tracing and logging into an own process and sends data over a shared memory. It is more optimized for a later analysis of larger amounts of log data and provides rich features for data (file) management and log analysis – including an UI. Luckily, both implementations use the same coding language which should make things easier; however, internally application B has dependencies to internal and external components which is not the case in application A.
With this trivial example it already becomes obvious where the complexity, risk and cost for a common logging system will come from:
- A business relevant decision must be made concerning the target feature set of the shared component. If just the minimum features are provided by the platform, there must be a strategy how more features can be added by the applications which require more. If all features of A and B shall be in the platform, A will probably not really benefit from the larger feature set – which questions the investments at this point.
- The architecturally most important decisions will concern the target quality of the shared logging component. Shall it be optimized for data analysis and large data amounts or for runtime throughput performance? Or both? If one of these example qualities is not met by the platform component, the concerned applications will not be able to use it, simply. Realizing optimization in both directions may (but must not) be difficult to realize when they impose conflicting requirements.
- Implementation wise the platform team must decide whether to base the platform component on solution A or B. In case A, it is likely that features that are provided by the used libraries in application B (“3 Modules in utility library for query engine and file management”) need to be re-implemented or that these external modules must also become part of the platform. In case B, the additional dependencies must be considered in the solution for application A as well. Also, case B demands for a user interface which includes a decision for UI technology which was not part of the other solution yet.
Later in this paper, I will outline a structured approach concerning the architecture and specially the qualities that need to be considered in a common component. For now, I hope it became clear that even if features look the same and have similar requirements in two solutions, the solution complexity is mainly driven by how the features were implemented and how they are used in the applications.
Infrastructure vs. Business Features
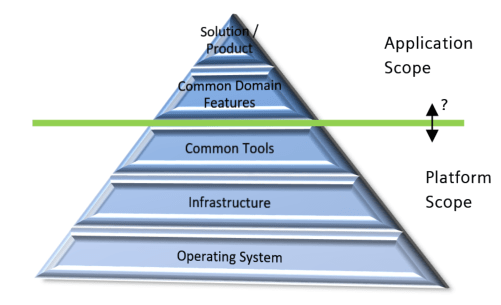
Nevertheless, every system needs supporting functions and some base infrastructure to function properly. The pyramid on the right illustrates a typical setup. Beginning with the basic operating system we need infrastructure for data persistence and data exchange, runtime containers, configuration and other tools to finally create our market relevant features.
The potential of a software component or feature that is in the lower part of the pyramid to be re-used is quite high. The lower parts of the pyramid are of general purpose while features get more specialized the higher we move up in the pyramid. Highly specialized features are typically rarely re-used by other applications unless they can be configured for related and similar use cases. Here is an example of feature clustering from the logistics domain that would map to such a layering:
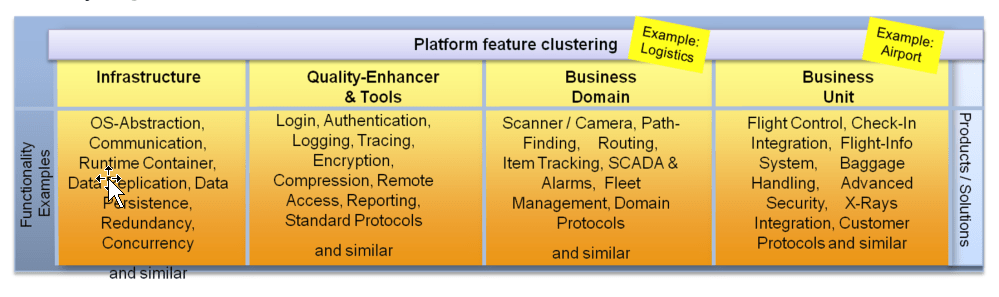
Figure 6: Feature Clustering Example
As defined above, every layer in this schema could be designed as a platform for the next layer. And so every layer needs a dedicated scope and a set of features it provides.
When planning for a platform that is distilled from multiple existing solutions, it is crucial to separate infrastructure features from business features in the discussions. It appears logical that it could be a goal to realize as much business features as possible into the platform, to gain a maximum benefit over multiple applications. But this might be paid off by the flexibility that is required in these features.
It will be more and more difficult to provide features in the upper layers of this pyramid that fit the requirements of multiple applications or solutions. This can manifest either in the diversity of functional requirements or, and this is the more difficult case, in the diversity of non functional requirements. In the logging-component example above, it will be possible to make the platform component configurable in terms of e.g. output into files or database. But it will be more difficult to optimize into two different performance dimensions as required by the applications. This is also somehow natural; otherwise it would not make sense to build different products or solutions at all. They differ in their business features; it is just the question how much.
So, a clean decision will be required how much of the existing business features can be generalized to become part of the platform. The generalization efforts require configurability and flexibility as new qualities in the existing features which typically increase the solution complexity and so the cost for the feature provisioning. In the most cases it is advisable to start with a harmonization of the infrastructure and work up the pyramid step by step. In the simplest case, the platform provides pure infrastructure services and some general tools. On the other hand one can think of a fully configurable product base platform that covers 90%+ of the application features.
General Non Technical Consequences
When transforming the applications and solutions in an organization from individuals to solutions based on a shared platform, not only technical work is required in writing and changing software.
In my paper “Best practices in Platform Development – Avoiding Cost Traps right from the Start” I provided a set of aspects and issues that need to be taken care of beside the pure development of platform features. The establishment of a platform that has multiple clients (internal and external users of the platform) comes along with a new set of task, liabilities and responsibilities that all lead to increased costs and risks in the platform project. Also the organization and the processes around the platform development will need special attention and proper adjustments. In product line engineering, these topics are also discussed intensively and PLE also provides several best practices in the area. An example is the maturity of an organization to drive global optimizations over platform and application / solution projects.
Here is a short summary of the non technical aspects that can be found in the mentioned paper:
- Ensuring that the platform development is business driven & strategy aligned
- Make sure that the key persons (e.g. architects, key developers) understand the client’s domains and their cost drivers and the platforms strategic rational
- Do not spend effort on things that do not contribute to the business cases (explicit exclusion)
- Creating proper awareness of sponsors expectations and political forces
- Every sponsor or client may have other expectations, be aware that you cannot serve all at the same time
- Expect that the clients will generate conflicting requirements for the platform
- Balance the different client’s demand and the development capacity of the platform team
- Incremental approach, continuous delivery is advised – foster early feedback
- Prioritizing platform feature quality over platform feature completeness
- Prioritize, Prioritize, Prioritize together with all clients (they have all different ideas of what is important)
- Embrace controlled change, priorities and scope will change due to internal or external forces
- Quality is more important than a broad feature set
- Be able to always (!) deliver a product-quality release
- Enforcing real architectural governance
- Install a change control board which decides on prioritization (roadmap) for all requested changes
- Even under high pressure, do not allow quick changes before clarification of the impact to other clients is done – rollbacks are very expensive
- Putting a focus on the usability of the Platform on developer level (developer habitability)
- Provide developer level information for effective and efficient work with the platform
- Provide tools and concepts, focus client’s productivity
- Once an interface is released and used, you will not be able to change it easily
- Hardening of platform against malfunctioning plug-ins and client apps
- When providing a framework to build and plug-in additional functionality, ensure the platform stability
- Expect that plug ins and apps will degrade the platform quality (e.g. performance, stability)
- Implement measures to securely handle plug ins, which includes a checking and release process for externally developed modules
- Providing Training, Service and Support for developers and users
- Provide a variety of options to build platform knowledge on client side and do ongoing consulting
- Install a variety of options for reactive support
- Include features in the platform that support the support activities
- Balancing the coupling of platform team and Product / Solution teams
- The platform team should keep constant contract with the client to understand needs and problems
- Also, the platform team must not be disrupted by constant external forces (e.g. emergency issues)
- Defend the platform project goals
Approaching the Migration
System Architecture Challenges
Make 3 out of 2 and erase duplicates
The first challenge at hand is to define what will be platform scope and what will remain application / product / solution scope. As a starting point it is required to be clear about the features that are realized in the current applications / products / solutions, from the base infrastructure up to the business relevant features. In addition it needs to be clear which future requirements the platform shall support. In the following sections it is assumed that the realizing organization is following general SW development best practices and processes that include a proper requirements engineering.
Glossary and Domain Model
In PLE, the methodology of domain analysis and domain modeling is advertised to start the process of structured analysis. Here, the term “domain” stands literally for a cluster or type of functionality or for a specific business segment.
Here are some examples:
- Technical domains
- Operating system functions and resource handling
- Communication infrastructure
- Data storage infrastructure
- Security aspects like encryption or authentication / authorization
- Configuration infrastructure
- Logging and Tracing infrastructure
- Application and component hosting & control
- User Interface Framework
- …
- Business domains
- Process Control and Visualization (SCADA)
- Factory Automation
- Computer tomography
- Remote service
- Customer Relationship Management
- Quality Management
- Overload protection
- …
There are many different opinions for what a “domain” is in this context, but to be practical here I like to limit the term to either technical or business aspects. An aspect of the system may be located in one or multiple domains, but typically there is a dependency between a business feature and (one or) multiple technical features on which the business feature relies. So also these domains have overlaps and logical dependencies.
The purpose of the domain analysis in PLE is to determine the assets and features within the domains in order to build the basis for an analysis on commonalities and variabilities among the business domains. With the domain model spreading over the different solutions and applications that are in scope for the platform migration we create the basis for a common understanding and cooperation. So, the very first artifacts that shall be created are:
- A glossary that defines all terms within the domains, including the specialties of each of the existing solutions. This is especially valid if both existing solutions define different things under the same terminology. Typical examples for needed clarification on a technical level are terms like “service”, “component”, “message”, “event” and similar. With the glossary it is made sure that all involved parties understand the same thing for the same word. So, if an aspect shall be realized in the platform, all stakeholders must have the same understanding what they will get to avoid wrong assumptions of platform deliveries.
- A domain model consisting of entities and relationships from the problem (business) domain of all existing solutions in scope. All entities within the business of the solution should be known and it should be clear how they are related with other entities. Since the existing solutions from which the platform should be derived will differ in the way how they model their problem field, it is important to know where the differences are. This model is a significant tool to discuss on the scope of the solutions and how much of those elements are the same in all solutions. Here is an example domain model for a measurement domain (simplified):
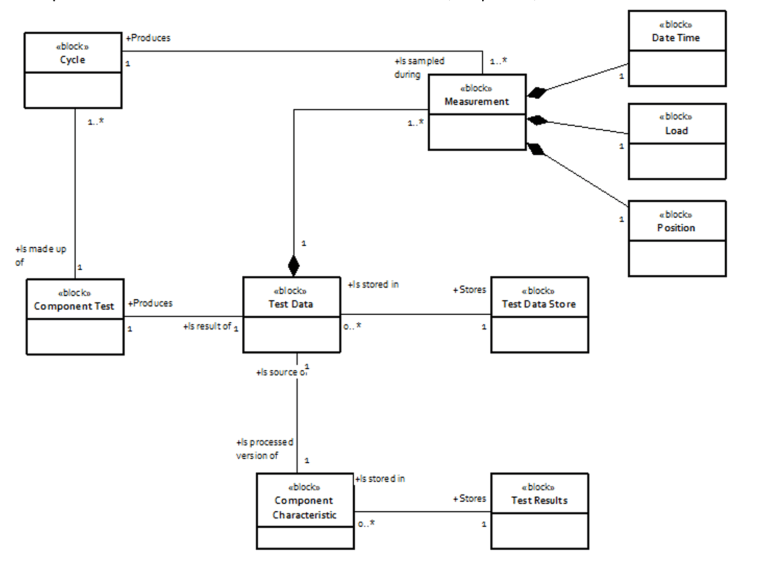
Figure 7: Example Domain Model
- A technical model where the technical entities and their interaction should be modeled. This includes the technical infrastructure of both solutions and their interactions with the focus on the technical problem domain (for example servers and mobile devices for running the SW, a web server for hosting a web-application, database products, application servers…) Alternatively, the architecture documentation, especially the component view and the deployment view of both solutions can be used instead – if the two documents are of equal quality and abstraction. Nevertheless, it will help in defining the technical infrastructure of the platform when it is clearly outlined which components, products and technology are used on each solution. Such a basic comparison of used technology and technical infrastructure also provides first indicators about the technical similarity of the solutions and the required work to do in order to harmonize them (if that would be required later on).
In summary, the approach is a domain driven development approach. There is several literature that can be consulted for more information, e.g. [R8]. The important point here is to ensure that a common understanding of all applications in scope is found by building a shared terminology and modeling the problem domains. Often misunderstandings and wrong assumptions are reason for many problems which could have been avoided with such simple tools. Creating the model forces the groups of each solution to agree on the common understanding in a cooperative way which is a vital foundation for the upcoming work and so shall not be underestimated also from a team-forming point of view as well.
Feature Models
The basis of the software product line engineering methodology is the explicit modeling of what is common and what differs between product variants. Feature Models [R5], [R9] are frequently used for this.
Once the terminology is clear and the problem domains on business and technical level are understood, we now should ensure that it is clear which features every solution implements and in which quality it is provided. The latter is an addition to the regular feature models that are typically found in the PLE frameworks.
Basically, this can be done as it was outlined in the logging-component example above. PLE advertises the creation of a feature model and a quality model for the entire target market – which includes the platform and all products that will be based on it. If such artifacts do not yet exist for the solutions in scope, then they need to be created. The important part is that the solutions become comparable on feature level, so that it is possible to walk through the list of each solution and indentify functional equivalents. Double features are then automatically candidates for the platform scope in a first stage.
However, the pure functional feature as a name in a long list is not sufficient for a judgment on the platform scope. The logging-component example showed that also the details on the implementation are substantial for a cost and risk estimation later on. But let’s handle one after the other.
A feature model for the above mentioned layers of the system – from infrastructure up to the business features – is required. This can be achieved in multiple ways, here are two examples:
- Reverse engineer the features starting from existing code (e.g. classes and components) and work the way up to find the realized business features – bottom-up approach
- Start with business features that were tested and accepted (the product owner or test department should be able to provide this) and derive the required lower level functions by resolving the dependencies in the code – top-down approach
Depending on the architecture (e.g. modularization) and documentation of the existing components this task may generate different efforts for each existing solution. In some cases it might be directly visible from code components and their public interfaces which features are in which part of the system, in other cases the features are not directly visible. The better the existing solutions are documented, the faster this step will be done. Of course, knowledgeable engineers and testers can also help to reverse engineer the feature set if no documentation is available.
Please refer to PLE books and similar resources for details on the options how to actually format and prepare a feature model. Here is a very simple example of a weather station feature model:

Figure 8: Example Feature Model
Quality Models and Feature Implementations
As mentioned above, the non functional aspects of the existing solutions build the third larger building block that will allow us to find a good scope for the platform in respect to the required efforts.
Every system architecture, and so the solutions that are in scope for the platform approach, is driven by the non functional qualities it has to fulfill. Optimally, every existing solution should have a quality model that defines a clear prioritization of qualities that were focus during its development. Even if such a quality model does not exist formally, it should be derivable from the non functional requirements of the solution. And even if such requirements are not explicitly available, the code will definitely be optimized towards certain non functional aspects. So, typically all mature solutions are optimized for one or more qualities (e.g. security, performance, scalability, flexibility…).
It is very important to consider this aspect when analyzing the realistic chances, risks and costs for a refactoring of existing solutions to a shared platform. Reasons for this statement are:
- Non functional requirements will drive the strategic architecture of the platform
- If non functional requirements are conflicting, the platform might not be able to fulfill all solutions’ requirements. Optimization in all directions does not always work.
- Addressing non functional requirements on system level (strategic design) has system wide impact and so may have vital impact to costs and risks.
Actually, we will need two levels of qualities that were of high priority during the development of the existing solutions:
1) The global optimization quality goals, which includes strategic design decisions that have solution wide impact. For example, a solution design would be different if it was optimized for security or if it was optimized for usability/performance. So we need to understand what drove the development of every solution. Here a quality tree can be used as it is provided by several PLE frameworks. Please find below an example of a quality tree that includes concrete non functional requirements.

Figure 9: Example Quality Tree
2) The concrete tactical design for every feature. This was already shown in the “the devil is in the detail” example above. Even if two solutions implement the very same functional requirements, the implementations may still differ in their optimization for non functional aspects. So, when realizing the feature in the platform, there must be a decision made which optimization direction shall be chosen for the individual features – which direct impact on the platform’s clients.
In addition to this, there is another dimension which also typically has large impact on the cost for extracting and reusing an existing feature. It is the data model and the data handling that is required for the feature.
Data Model
Almost every feature and function, unless it has it focus on algorithms, will have data involved. Data is provided at the interfaces of the modules and features and data is stored in databases in memory and in files.
In general, three main aspects are to be considered here:
- Logical Data Structure and Types (how it is organized)
- Physical Data Structure and Types (how it is stored)
- Data Semantic (what it means)
- Data Synchronization Paradigms (how data is accessed and how data consistency is ensured)
Coming back to the logging-module example from the beginning of this paper, let’s check what we need to consider in order to create one platform feature from the two existing solutions. In this example we first need to focus on the data that is written to the log files / log database. Secondly the question on how the interface looks like that other parts of the solutions may use is in focus.
When analyzing the logging feature realization in both existing solutions, the data structure needs to be compared on a logical data structure and on a physical data storage level. The logical structure defines the data fields that are used and how they relate to each other. So, for instance, in a relational database this refers to tables, columns and foreign keys. For the logging component this refers to the data representation of the log entries. One solution may for example store the log entries flat one after another, the other solution optimizes for disk space and holds redundant information in a dictionary (e.g. a message type text). Such differences in the logical data structure can result from optimizations towards certain qualities like performance or disk space utilization and so directly contribute to the issues I outlined above. They could also result from technological considerations, for instance the used database technology. On a physical level it becomes interesting how the data is actually stored on disk. In the file storage example, the file might be written in plain ASCII text or as binary blocks. Another more extreme example is the usage of cloud storage concepts that utilize a highly distributed and not directly accessible data store.
Understanding these differences is important in order to allow proper design decisions for the platform feature and understand the implications if existing solutions need to be migrated to it.
Now let’s assume we have a field called “timestamp” in all relevant implementations of the logging component. Even if all share the same name of this data, still the semantics behind this data field may be totally different over the several implementations. In one case the implementation may interpret a UTC timestamp with millisecond resolution, in another case “timestamp” might be a relative value in microseconds from the last recorded event (diff measurement). Such differences in semantics of data directly point at the realized business logic of the component and the concepts that were applied. Here different solutions quickly become incompatible, even if the data structure is the same.
In summary, the aspects mentioned here can be understood as the task of data integration, please refer to [R10] for a deep dive into this topic.
Another dimension that should be considered when comparing two existing components is their different concepts in synchronizing data. If distributed applications are storing data into a common database or file (e.g. our logging component exists multiple times in a concrete system), the problem of data synchronization comes into scope.
The CAP theorem presented by Eric Brewer, states that “of three properties of shared-data systems; data Consistency, data Availability and tolerance to network Partition, a single system can only achieve two at any given time”. Given that in larger distributed scale systems network partitions are present – either consistency or availability has to be relaxed. So, also in data synchronization we have to consider optimizations regarding these qualities. This includes concepts for transactions, consistency checks, locking and avoidance of race conditions and some other aspects. If the different implementations of our logging component example use different paradigms and concepts here, the differences also need to be considered in a shared component. This may still apply even if data structure and semantics are equal.
C/V Analysis and Scoping the Platform
Up to now we collected the following information for all existing solutions that are in scope of the platform migration project:
- Domain glossary and problem space domain model
- A technical model of the used technology and infrastructure
- The feature model, a pure functional view on the existing solutions
- The general quality model along with the concrete feature implementation optimizations
- An analysis on data structure, data semantics and data synchronization
In summary, in order to optimally be able to judge on the options for the platform scope, a list of comparable features along with their implementation details should be generated based on a domain model.
Based on all this information, now it can be checked – one feature after the other – how much they really differ in the existing solutions and how much really makes sense to become a shared component.
The mapping of pure functional blocks and features shall be a starting point, but if a feature shall be realized in the platform – it must be clear what optimizations shall be taken over and how the underlying data model shall be chosen. These decisions have direct influence to the business case and the economic justification of the platform – especially when it is intended to migrate the existing solutions to the new platform as soon as it is available. As mentioned above, a concrete feature may not be useable for a solution if the required qualities are not met. Or at least a solution would require massive changes in order to use the platform implementation instead of its own if the paradigms for data exchange, data synchronization and general interfacing are not matching.
The functional scope of the platform should be built up beginning at the base infrastructure and should end at the high-value business features. Consider the differences in functionality and the differences in implementation to draw a border line between platform and solution / application / product.
Technology Harmonization for Infrastructure
Literally every software system is based on some infrastructure on which it relies and which it uses to build higher value services. Like with the term “platform”, the term “infrastructure” is not sharply defined. The infrastructure that is used in a concrete system can also be provided as platforms – so these two terms may overlap a bit. Other terminology for infrastructure is “middleware” or “generic tools”.
With “infrastructure” I refer to all parts of a system that are building the foundation for the execution of our business logic. Here are some examples:
- The hardware platform and its interfaces like interrupts and I/O ports
- The operating system
- A runtime container
- A service locator
- A framework for parallel code execution (multi-core)
- The persistence framework and a database
- The inter-process communication system (e.g. messaging, RPC, RMI…)
- A business rule engine
- A web-server with servlet container
- The .Net framework
- The Java 7 SE JDK
- A scripting engine and interpreter
- A browser like the internet explorer
- A web-app engine
- A cloud framework and API like Microsoft’s Azure
- Distributed databases like Amazon’s EC3
- A virtualization stack along with management tools like VMWare
- The network with routers and switches
- A data analytics systems
- Tools for authentication, authorization and encryption
- …
There is much more to mention. Infrastructure will always include aspects from the physical level, like hardware and its abstraction, as well as quite high-level enterprise aspects like a service oriented infrastructure, messaging or cloud stacks. It contains basic services that all together build the environment in which a concrete business feature will be deployed and operated. There are many technical decisions on the way that all lead to the final setup.
When now a concrete existing solution shall be migrated to make use of a platform and its features, it is important to understand how much of the infrastructure needs to be harmonized in order to allow a migration.
A simple example:
Solution A is using an Oracle Database via a JDBC driver from a native Java application. The java application is standalone, so does not need a special runtime container. Its UI is also written in Java (Swing).
The platform was also written in Java, but makes use of an Enterprise Java Beans (EJB) application server that handles cluster functionality. The platform uses the Java Persistence API (JPA) in order to talk to a mySQL database. In order to make use of the enhanced scalability and availability that comes along with the platform, solution A shall be migrated to make use of the platform features and its provided infrastructure.
This example shows that now solution A and the platform had different decisions concerning their infrastructure during their development. In order to allow a solution A+ that integrates into the platform, the infrastructure needs to be harmonized – in this case this means a major re-design and a new architecture for the existing solution A.
Harmonizing the infrastructure may lead to substantial changes in existing solutions. However, such a harmonization may also lead to substantial improvements. The major benefits in a harmonization of used infrastructure are:
- Reduced complexity through reduced technological diversity
- Reduced need to hold special knowledge for the different tools and frameworks
- Reduced need for updating and maintaining infrastructure
- Reduced cost for support and licenses for infrastructure components, chance to negotiate higher volume license agreements
- More easier exchange of people and code between solutions and products
- Increased level of understanding among solutions and platform teams
- Chance for leveraging innovations from new technology
However, as outlined above, there might be a specific reason why a concrete product or solution picked a certain infrastructure for its design. Non functional qualities are vital to the success of a solution and a migration to another (platform) infrastructure might not be possible because of non functional demands. So, again, this needs to be carefully checked.
The concrete efforts for a harmonization of infrastructure may be very high, depending on how good the infrastructure was encapsulated and how dependant the business logic is to the infrastructure APIs on code level. Not rarely such a decision can mean a re-writing of the business features because of the impact of the technology decision.
Let’s make two more prominent examples from different domains which both require substantial work for a migration:
1) A SW system for an embedded device, like a micro controller based automation device, was designed for a single-CPU machine. The SW was written in the assumption that the infrastructure is a single-core CPU and that all runs sequentially. Now, the hardware is upgraded to a 4-CPU board and comes along with a new HW abstraction layer infrastructure. In order to make use of the new hardware and its API, the SW system at hand needs to be migrated to the new infrastructure. This actually means that new interfaces must be used and the SW must be made fit for concurrent and parallel execution. This does not only imply changes in the code logic but also means to adapt to a completely new programming model and making use of parallel concepts. For instance the infrastructure may demand a use of Intel’s multi core APIs or e.g. the new C++ 11 language features for multi-threading. Our business logic now is not compatible and a migration to the new HW-platform is a substantial change that needs a new implementation.
2) A distributed web application was written for the installation into dedicated web-servers with dedicated databases. It is using a local open source database instance and was build with an early version of the Microsoft .net framework. Now, with increasing customer counts, the system needs to grow further. On the other hand, new web applications were built with Microsoft’s Azure and now make use of the scalability and the business model that this cloud offering provides. For these newer web applications, a platform was created which eases the use of Azure and already provides some tools for the target market. In order to now make use of this new platform in the existing, old, distributed web application, the web application must be made ready to run on an Azure infrastructure. This introduces new conceptual aspects like the messaging, persistence and identity management (provided by Azure APIs) that now needs to be adopted by the existing solution. This also will lead to substantial changes in the existing solution in order to adapt to the new infrastructure.
Of course, there are also examples for easier harmonization tasks that will not have such a substantial impact. Nevertheless, for a realistic calculation of risks and cost that need to be considered it is really important to understand how much infrastructure will have to change for existing solutions if they shall be based on a new (or existing) platform. And please note: Not a single new feature will be realized with all the effort – this alone imposes a real challenge in motivating sponsors for the investment.
If the infrastructure does not have to change much, the chances for a successful migration will be much higher due to less technical risk and increased economical benefit.
Because of this fact, an organization may also think of other options that favor a less integrated and more loosely coupling of existing solutions and new solutions based on a new platform. Then, we turn the approach from a platform migration task to an application integration task – which may be a more economic alternative.
Refactoring – Extract modules and reuse them
Up to now we mainly analyzed the impact and cost of a migration of existing solutions to a platform approach. Now, we will have a look at the process of extracting an existing module from a solution and make it a shared component that can be used by other solutions.
- Feature Isolation and encapsulation
First of all, the feature that shall be extracted needs to be isolated over all layers in the solution architecture. So, if the feature has UI elements, some business logic and some data to be stored in a DB, the entire stack needs to be isolated. This means that all functionality of the feature should be present in source code files that only include code for this feature – nothing else. The goal is to remove this code from the solution later on, so it must be possible without affecting any other features. With this, the selected feature provides a clean interface to its functionality that is used by the existing solution.
- Refactoring testing – building a safety net
After the isolation, the code shall still work in the same way as before the isolation within the existing solution. So, a safety net made of test cases is required, which will ensure that. If there are no test cases that can proof the functionality of the selected feature before and after the isolation, we will not be able to find any introduced flaws and so introduce a considerable quality risk.
- Transferring the code
The isolated code shall now be transferred to the build system of the platform and removed (or excluded from the build) on the solution side. It might be required to deal with external dependencies in order to allow a build, but in the first attempt the logic shall not be changed. After building the binaries, they should be used in the solution as external dependency and the test cases shall be executed again. This will ensure a binary compatibility and makes sure that the now external references work in the existing solution. The API of the new platform component also is checked for proper functioning.
- Incremental Harmonization
Now, after the new feature serves the required interfaces to the solution, it can be changed internally to match the platform’s architecture, infrastructure and data model. This should be done incrementally, one aspect after another. After every increment it may be useful to run the solution test cases again to get a continous feedback on the quality of the change. During this process, the interfaces need to be stable while the inner workings are refactored.
- Adding new variability
Once the new platform feature is now a clean component of the platform with harmonized infrastructure and architecture and it has been validated OK from the solution to work properly, we now can add new features to the platform component or modify its qualities. Depending on the former analysis results the new component shall have a broader scope then it was originally provided by the solution. Other solutions may require variations of the component that can now be implemented. However, be aware that any changes in functionality or quality may not impact the interface that is already used by any solution. If interface changes occur, the efforts on solution side need to be considered as well.
NFRs as major Risk for Failure
As outlined several times above, the non functional qualities of the platform features are crucial to the acceptance in the existing and new solutions. However, there are some general things that should be mentioned in addition because of the system wide impact.
Typically it will be expected that the platform will support the maximum of all solution requirements concerning non functional qualities. It is fast enough, scales enough, is stable enough and it is secure enough to satisfy all solution demands. Realistically not all requirements will be met, especially not in the first versions in the platform – due to the simple fact that optimization in multiple directions is either hardly possible or associated with increased cost and time-to-market. So you need to manage the solution’s demands and make transparent which qualities the platform will be able to archive in which point in time.
At his point it shall not be forgotten, that the introduction of the platform into existing solutions might increase the level of abstraction and indirection and so generates a performance penalty on certain functions.
In addition, a new requirement will rise that typically is not named explicitly until it becomes obvious. The term “developer habitability” has evolved in computer science over the last years and names it quite good. It means that the developers of solutions which are built on top of the platform should be supported in realizing a concrete system both efficiently and effectively. The platform must be attractive to be used; people shall like to work with on a daily basis. There are many aspects to consider here in order to increase the usability for the SW engineers, architects, developers and testers that want to create concrete solutions based on the platform. Here are some examples:
- Provisioning of developer guidelines concerning the programming model and used technology
- Provisioning of How-Tos and cookbooks for a quick start and a motivating introduction
- Provisioning of working examples in code and a reference architecture
- Provisioning of tools for efficient development like intellisense support, error analysis tools or configuration wizards
- Focus on essence and simplicity in the platform concepts and architecture in order to avoid steep learning curves
- Focus on a stable and usable API with proper documentation
- Focus on a durable runtime stability
- Consistent concepts (one solution per problem) for error handling and configuration
- Focus on expressiveness, e.g. when generating error messages
The acceptance of the platform provisioning will be a major success factor. If developers of the solutions do not accept the platform because it is not usable – the platform is useless. It must be understood, that this kind of usability requires other measure then the “common usability” for end users.
Development Processes
PLE defines two different development processes: The domain engineering (creating the platform) and the application engineering (creating the solutions). With the introduction of the platform into existing solutions, the solutions’ development will now depend on the releases from the platform team. It sounds logic and simple, but this fact shall not be underestimated.
First of all a development team along with responsibilities for the platform needs to be created. The team needs to establish a platform development process which also takes into consideration what the solutions require in terms of release cycles, testing periods and roadmaps. The linkage needs to be synchronized and they will have dependencies. An explicit management of these issues is vital to the success of the platform and the solutions that depend on it.
Dealing with existing Installations
In contrast to a green field project, existing solutions typically have an installed base. Instances of the solutions were sold to the customers who use the solution in productive environments. It now heavily depends on the type of solution at hand how much a migration of the solution to a platform approach will impact the installed base.
After a solution was split into a platform part and a new solution part (it was migrated to the platform approach) it will be released as a new major version. Depending on the business model, the technical dependencies and the type of solution, it might now be necessary to upgrade the customer installations. Thus it is required to analyze the impact beforehand during the design time of the platform to consider aspects like update-concepts and backward compatibility as part of the qualities that the platform has to fulfill.
The difficulty here is again the diversity over the different solutions that will be based on the platform. It needs to be understood which demands rise from these questions and which update scenarios the platform has to support. As an example, we recall the data integration examples from above. If the requirement for the new solution release is to still support all customer created data sets, the questions concerning customer-data migration will raise.
Concepts need to be developed in the following areas:
- Side-By-Side installation or updating existing installations
- Migration of customer data, especially when the data model of the solution was changed
- Backward compatibility to external dependencies, file interfaces and similar externals
- Usability continuity, dealing with user experience and user expectations
- Carve-In of new and carve-out of old implementations (how long to support the old version)
In addition to the customer view, also the development and testing view needs to be considered. With the release of the new solution versions (which now contain the platform) the old versions will not suddenly disappear. They have a lifecycle as well and will still need maintenance, bug fixing and updating. Even if the carve-out is done quickly, the installed base of the older versions will need at least some support. So, a demand rises to support the old and the new versions in parallel, which will bind resources in your development and testing environment (people and equipment). The double efforts need to be considered in the total cost of ownership for the new platform as well.
However, during the design time of the platform and its associated solution migrations, it may be considered how this transition from the old world to the new world can be archived. In general, we have to possible extremes available:
- Revolution: A sharp innovation which will replace the old version with a new version in one big step. This typically involves a lot of changes in one major release. The risk for breaking changes is higher but also the transition may be much faster and allows to get rid of unwanted aspects. It also provides the chance for a larger innovation.
- Evolution: A transition over time in rather smaller steps with less radical impact. Here risks are reduced due to less complex changes. This typically helps with introducing change without larger side effects but it will become more difficult to realize bigger innovation steps. It also typically is slower and more complex to archive due to all the details that need to be considered in every step.
Introducing new organizational and social Challenges
When we talk about extracting a platform from existing solutions, this always somehow implies that we want to change the existing solutions as well. They shall use the platform features once it is available and so stop using its own implementation. They shall use the platform’s programming model, its infrastructure and maybe also its data model.
What has the platform to offer? Hopefully a technological innovation, more features and more quality as any individual solution could provide. The question about the justification and the need for such an effort will be raised on different levels on the way. Actually, the change which is introduced here does not only affect technical things like architecture and source code. It affects the people. It affects them in the way they need to think, in the way how they are connect with “their” solution and in the way they are convinced that all this is a good idea anyway.
The involved people, also called stakeholders, need to be convinced about the benefits of breaking up existing – and potentially successful – solutions to build something larger and even more successful. The problem here, the larger goal of a global optimization is often not seen in the local area where a solution was born. There is a natural resistance against the change, especially when the solution owner (e.g. a department) is successful even without any platform. So, questions may come up:
- Why should we abandon our working solution?
- Why should we wait for the platform to be completed?
- Who pays for the extra efforts, we do not see any benefit for our business?
- Why is the new platform less performing than our “old” solution?
- 6 months of work and not a single new feature, I will not pay for this!
- We have been successful with this solution for years and now we should change it? Why?
- Who ensures that this other platform team does even know what we need?
It all starts with the business cases and incentives. If the departments which own the existing solutions have to sacrifice any portion of their revenue for the sake of “some global optimization” they will ask for the return of invest. So a business case must be developed with the business owners of the existing solutions that convinces everyone about the economical justification for the project – even if individual people will have to pay more in the first place. If this is not given, there will be no motivation for the solution owners to do any change at all.
This done, the technical aspects will become important. The platform will only be accepted by the solution developers if it provides the correct features in sufficient quality along with acceptable developer habitability (see above). If solution architects or developers do not get support in using the platform or they see increased efforts in adapting it, they will jeopardize the business case with effort estimations for the migration. And they will find may flaws and issues at the platform if they don’t like the idea that somebody else will provide critical components for their solution on which they do not have full control.
It is not only that the solution architects and developers have to use the new platform APIs to reuse its functionality. It is also the case that they have to abandon some of their sovereign rights. Up to now they were fully in control of the code that builds their solution and now they have external dependencies. Typically people don’t like this and so they will search for reasons why not to do it. It is a human attribute which can only be overcome by motivation through conviction. They need to understand and believe in the good of the approach in the first place. That requires intense communication from the very beginning and really good reasoning. All stakeholders need to be involved and should be part of the decision process in order to guarantee a buy in. If people are just confronted with orders from their superiors – which in the worst case are not even explained – they will form resistance.
External dependencies were mentioned here as a loss of power of the own solution. This is true also in another dimension as well: Roadmaps and project planning. A solution that is based on a platform requires a stable release of that platform before the solution can be released. At this point, the technical dependencies turn into business relevant dependencies when it is about time-to-market and release cycles. The solutions may have external (customer driven) forces which urge for bug fixes, patches and updates. As long as the problems can be fixed on solution side, there will be no new problem. But platform issues will also be found which then will put the customer pressure of every solution down to the platform team. They have to deal with the conflicting priorities and have to service their provisioning. The solution teams will experience a reduced freedom and autonomy in their development which does not only have business impact but also will influence the motivation of the team. This should be considered.
The platform team therefore has to come up with a cross-solution roadmap and must be able to negotiate priorities among the solution projects. A strong leadership, transparent decisions and communication skills are vital for success.
In summary, the platform ownership means making tough decisions, communication is crucial when dealing with contradicting requirements even in situations of high pressure from different solution projects. The organizational settings and responsibilities need to be clearly defined so that all stakeholders do know at all times who can make the final call if tough decisions must be made.
Summary
Determining realistic economical benefits and risks is quite complex and requires a sound analysis of the exiting solutions. Even if the functional view indicates a high potential of reuse, the non functional qualities that are required may still be contradicting. In summary, the concrete implementations play a major role in determining the impact of a migration to existing solutions. If it is the goal to extract features and at the same time harmonize infrastructure, substantial refactoring might be required that requires a lot of effort without providing new features.
The process of identifying a scope for the platform can be driven by the tools and frameworks that PLE provides: Domain Modeling, Feature and Quality Models, Commonality / Variability Analysis and the like. PLE so provides a good framework for brown-field migrations as well, even when it needs to be tailored to the concrete case.
When we plan to change the rules for solution development, we are well advised in not forgetting the people which are involved. Considerable efforts should be planned to involve all stakeholders early, to make them part of the decision making and to motivate the approach based on a solid business case for the platform. Developer habitability shall not be underestimated when it is about the acceptance of the platform in the solution teams.
As a rule of thumb, the diverse PLE literature claims that a platform feature will cost about 2 to 4 times more as the very same feature when it was developed as direct part of a concrete solution or product. This is due to the increased quality demands and the realized variability and flexibility. However this number aims at a green field PLE approach where no existing applications have to be touched. Extracting existing features from existing solutions may be quicker and less effort might be required if the platform follows the same implementation concepts and uses the same infrastructure. However this is rarely the case. Typically a new platform uses innovative or at least more modern infrastructure and concepts so that existing solutions and platforms become less similar on implementation level. With this, the migration efforts on solution side can increase significantly. It is hard to provide a similar rule of thumb for the Payoff Threshold in the case that we want to migrate existing solutions. It all depends on how much structural change is required. The cost for providing the platform will properly not as high as in a green field approach due to the existing code and experience, but the cost to use the platform in existing solutions will outweigh the provisioning cost-savings easily. Still, the approach might form a valid business case and is worth to follow – but it shall not be underestimated.




Leave a comment